Abstract
Projecting intermediate representations onto the vocabulary is an increasingly popular interpretation tool for transformer-based LLMs, also known as the logit lens. We propose a quantitative extension to this approach and define spectral filters on intermediate representations based on partitioning the singular vectors of the vocabulary embedding and unembedding matrices into bands. We find that the signals exchanged in the tail end of the spectrum are responsible for attention sinking (Xiao et al. 2023), of which we provide an explanation. We find that the loss of pretrained models can be kept low despite suppressing sizable parts of the embedding spectrum in a layer-dependent way, as long as attention sinking is preserved. Finally, we discover that the representation of tokens that draw attention from many tokens have large projections on the tail end of the spectrum.
notes
- models should learn to store information in places where they do not interfere with next-token prediction
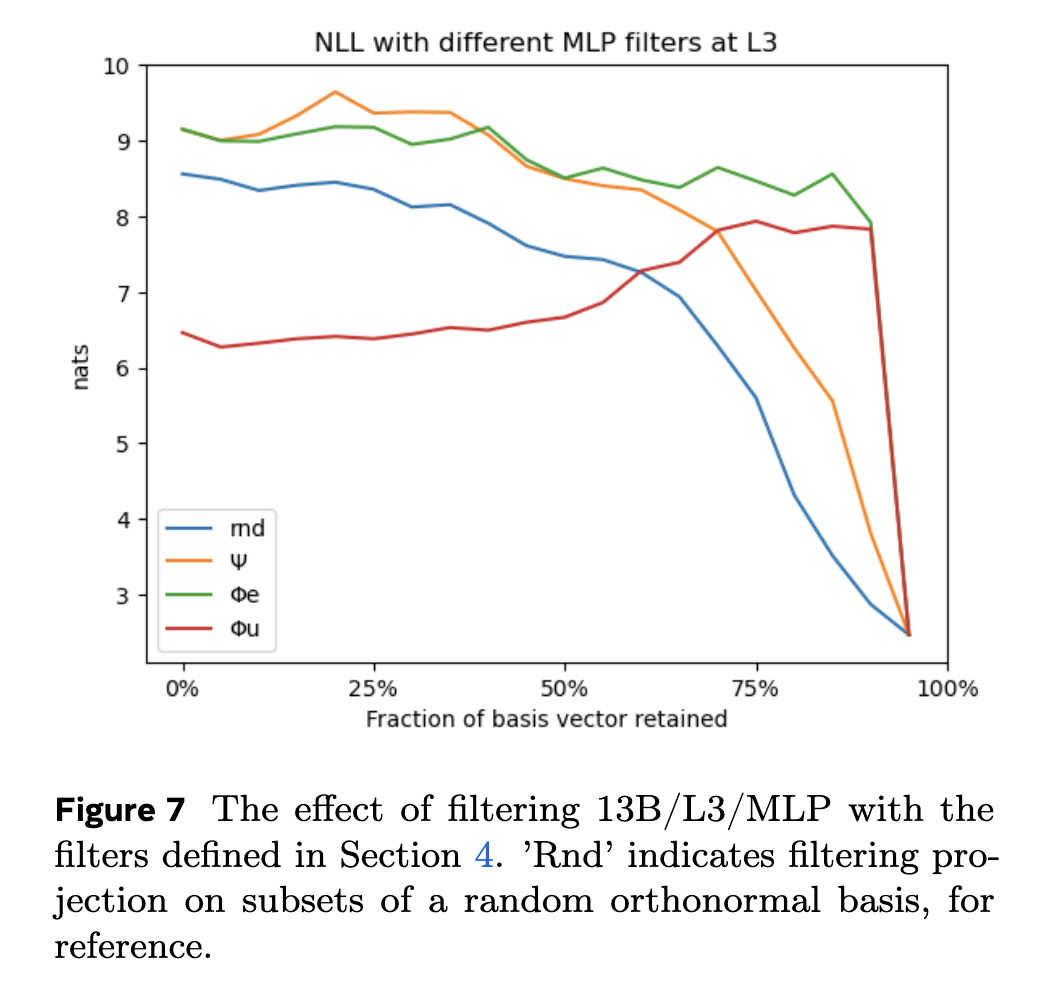
- so take the spectral analysis — lots going on in the dark subspace (last 5% of singular values of unembedding matrix)
- high mean/variance in the residual stream in these subspaces
- but these do not show up once you apply the unembedding!
- cutting off even a very small amount of the dark subspace makes perplexity jump by quite a lot
- attention sink! i.e. this is mainly present in token 0?
- i.e. disproportionate amount of attention to token 0 attention sink (artifact of softmax)
- need to allocate a constant amount of attention, so they have a “throw away” thing called an attention sink