After one step, the reparametrized linear model adjusts the slope more than the original model. This can be seen analytically. Consider the weight and bias of the linear model at initialization. The reparametrized model has initial parameters , . , so by the chain rule:
At initialization, , so the gradient update for the biases will be the same, but the gradient update for is scaled by . This explains the behaviour in Figure 1: the reparametrized model updates the slope more than than the original model. Note that this analysis does not necessarily hold after initialization, as .
A natural extension is to ask whether appropriately scaling the learning rate could erase this effect. We have , and
Setting means , which would mean . This is seen in
We can empirically test this:
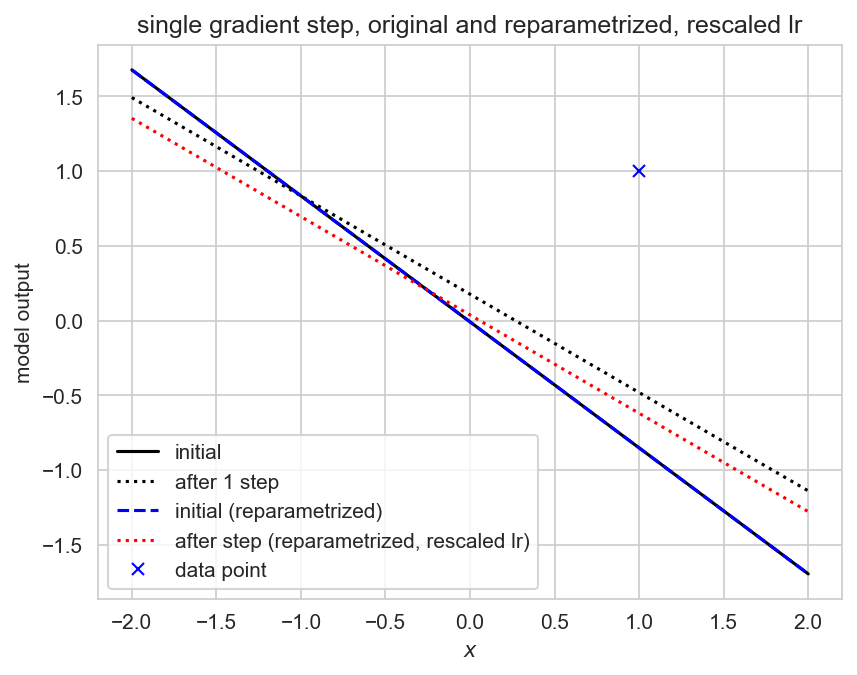
![[Pasted image 20250220224058.png]
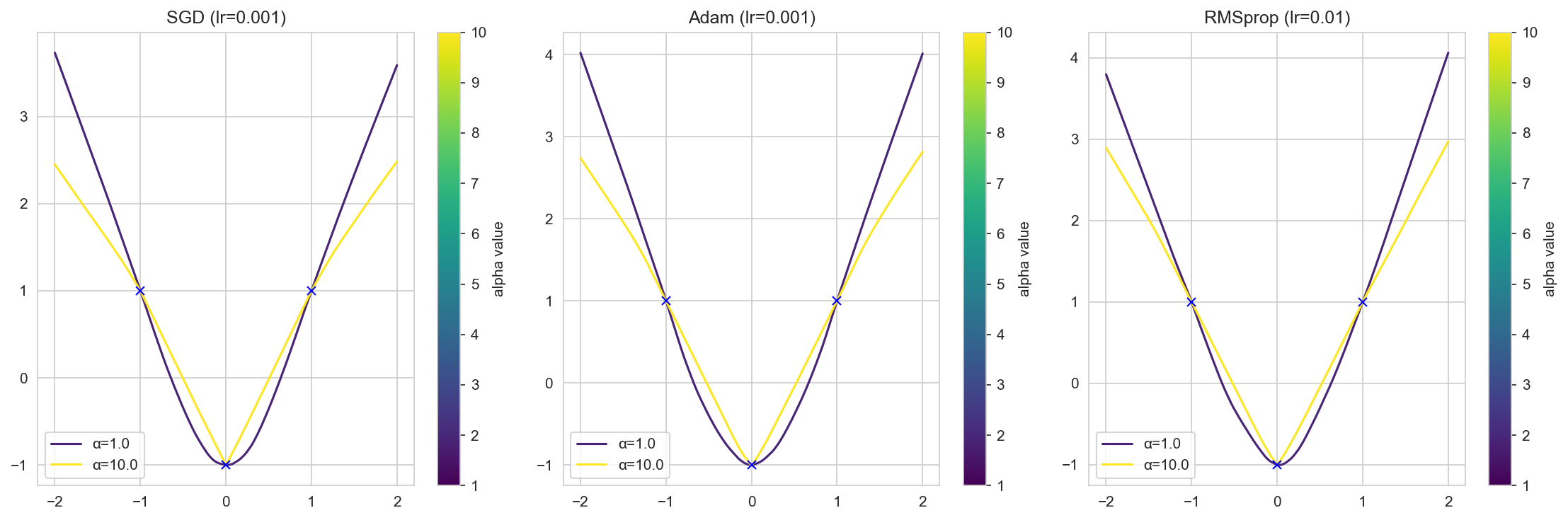
The